
2025. 2. 2. 19:49ㆍPaper/Ubiquitous AI
새로운 논문 읽기 방식 도전
이전에 작성한 논문 포스팅에서는 Abstract부터 Conclusion까지 주요 내용을 정리하고, 파트별로 느낀 점을 적었다. 꼼꼼하게 논문을 읽게 되는 장점이 있었다. 하지만, 그 틀에 매이다 보니 논문에 드러난 창의적인 생각들을 캐치하고 궁금한 부분을 더 찾아보거나 확장해 나가는 것이 부족하다고 느꼈다.
기존 방식도 내가 배워야 하는 부분이지만, 다른 방식으로는 무엇을 얻을 수 있는지 시도해 보기로 했다. 논문에 이미 파트별로 정리가 잘 되어있고, 해석은 번역기가 더 빠르지 않겠는가.
오늘은 틀을 먼저 만들어 놓지 않고, '흥미로운 내용' 자체에 집중해 보기로 했다! ⭐
오늘의 논문
KANG, Dong-Sig, et al. MIRROR: Towards Generalizable On-Device Video Virtual Try-On for Mobile Shopping. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2024, 7.4: 1-27.
* 오류가 있는 정보 또는 논문의 저작권과 관련된 문제가 있다면, 조치를 취할 수 있도록 댓글로 남겨주시기를 바랍니다.
온 디바이스 가상 피팅 시스템 MIRROR를 만든 이유?
MIRROR는 온 디바이스 비디오 가상 피팅(Virtural try-on, VTO) 시스템이다. 왜 필요할까? 온라인에서의 의류 구매가 늘어났고, 그 중 모바일 폰을 통한 거래가 큰 비중을 차지한다. 한 번쯤 온라인 쇼핑을 하며 이런 생각을 해본 적이 있을 것이다. '이 옷 나한테 잘 어울리는지 입어보고 싶다.' 사람들은 오프라인 의류 구매 과정을 가상 환경에서 실현하고자 한다.

위와 같은 이유로 MIRROR가 만들어졌고, 이전에 VTO를 제공하는 다양한 모바일 서비스들이 있었다. 3D 아바타를 활용한 TriMirror와 FxMirror, 2D 이미지 기반의 Zeekit이 있다. 3D 아바타는 현실적인 형태 구현이 어렵고 3D 데이터베이스를 구성하는 데 부담이 있었으며, 2D 이미지는 개인 사진을 업로드하는 방식으로 인해 개인정보를 침해했다. 설문 조사에 의하면, 사용자들은 개인 정보를 공유하지 않고 생생한 비디오 기반 피팅을 원했다.
VTO GAN 개발에서 해결할 문제
첫 번째는 데이터 불일치(Data discrepancy), 두 번째는 연산 부담(Computation burden)이다.
기존 GANs를 실제 세상의 비디오에 그대로 활용하면, 상당한 도메인 시프트로 인해 원하는 바와 다른 출력이 나올 수 있다. 도메인 시프트는 훈련, 검증, 테스트 데이터의 확률 분포가 실제 예측 모델을 적용할 데이터의 확률 분포와 다를 때 발생한다. PF-AFN과 같이 가벼운 VTO GAN도 많은 신경망과 모바일 GPU 자원의 부족으로 인해 모바일 환경에 적합하지 않다.

DIVTON과 VITOFF를 통한 문제 해결
Domain-Invariant VTO Network(DIVTON)는 일반화를 할 수 있는 VTO GAN이고, Virtual-Try-OFF(VITOFF)는 경량화된 VTO 추적 방식이다. DIVTON은 자연스러운 이미지로부터 세부적인 인체 정보와 도메인 불변적 특징을 추출한다. 큰 단위의 인체 분할 모델과 Appearance Flow-based Network(AFN) 프레임워크를 통합함으로써 일반화 성능을 높인다. 하지만, 모바일 장치에서 연속적으로 DIVTON을 실행하면 연산 부담이 발생한다.
따라서, VITOFF는 합성된 프레임에서 경량화된 포즈 및 의류 추적 기능을 통해 DIVTON의 실행 빈도를 줄인다. VITOFF는 DNN 연산 없이 픽셀 단위의 밀집 변형 흐름을 생성한다. 개별 픽셀을 추적하지 않고 신체 영역 내 주요 특징만 추적하는 선택적 광학 흐름을 사용한다. 신경망 계산을 최소화하고, 고품질 키포인트 선택을 통해 비디오 VTO 품질을 향상한다.
MIRROR 연산은 Preview 단계와 Runtime 단계로 나뉜다. 전자는 비디오를 분석하고 재사용 할 수 있는 정보를 저장하며, 후자는 동일한 비디오에 다른 의상을 적용하는 VTO 속도를 올린다.
MIRROR 앱이 처음이라면? 이렇게 사용!
당연히 MIRROR 앱부터 설치한다. Preview 모드에서 사용자의 전신이 나오는 비디오를 녹화한다. 녹화 영상은 MIRROR 저장소에 보관되며, 개인 정보 보호를 위해 외부 쇼핑 앱으로 유출되지 않는다. 사용자가 온라인 쇼핑 앱에서 맘에 드는 옷을 고르면 VTO 리스트에 추가된다. 리스트에 의류가 추가될 때 MIRROR Runtime 모드가 작동한다. 사용자 비디오를 선택한 의류를 착용한 VTO 비디오로 변환한다. 사용자는 최종 VTO 리스트를 확인하고, 쇼핑 앱으로 돌아가서 옷을 구매한다.

DIVTON의 도메인 불변성과 Warping 모듈
런타임에서는 파서가 없는 student DNN이 실행되며, 훈련 중에는 파서 기반 tutor DNN이 형태 흐름을 잡아간다. DIVTON은 도메인 불변의 신체 마스크 출력을 생성하며, 부드러운 배경 재합성을 보장한다.
PF-AFN의 경우 팔이 몸통에 겹쳐지면 문제 사례가 발생했다. 파서 기반 GAN이 겹쳐진 팔과 몸통을 더 잘 구별하지만, 단순히 AFN에 추가하는 건 좋지 않다. 무거운 전처리 네트워크의 추가는 계산 부담과 오류 전파를 유발하기 때문이다. 어떤 종류의 인체 정보를 어떤 방식으로 경량 도메인 일반화에 사용할지 선택이 필요했다. 전처리 네트워크, 파싱 포즈, 덴스 포즈 중 파싱 정보만 사용한다. 또한, 도메인 시프트에 취약한 ATR이나 LIP 데이터셋 대신 PPP 데이터셋으로 ResNet-101 파서를 학습시킨다.
큰 범위의 파싱 결과는 변형 모듈(Warping module)에만 입력한다. 생성 모듈(Generation module)에 이러한 정보를 추가하면 세밀한 합성을 방해하기 때문이다. person(tut)과 person(out)은 같은 옷을 착용하므로, parsing(tut)가 parsing(out)을 감독하여 픽셀 수준의 교차 엔트로피 손실을 계산한다. 파싱 제약 손실은 팔과 상체가 겹치는 부분을 구별하는 데 중요한 역할을 하며, 생성 모듈은 이러한 파싱 손실로 학습을 진행한다.

grid_sample 레이어를 CPU에서 실행하고 나머지 작업을 GPU에서 실행하면 GPU-GPU 통신이 자주 발생하며, 변형 모듈에서 많은 시간이 소모된다. 5개의 상관관계 레이어를 포함하여, 사람과 의류 이미지 간의 모든 픽셀-픽셀 관계를 반영하는 변형 흐름을 생성하는데, 이때 2개의 상관관계 레이어를 제거하였다. 사람이 움직이는 범위가 제한되므로, 의류에서 인접한 픽셀도 유사한 흐름을 가질 것이라는 근거가 있었다.
VITOFF의 키포인트 기반 변형 흐름과 박스 추적
VITOFF는 Preview 단계에서 큰 범위의 파싱 기반 선택적 키포인트를 이용한 광학 흐름, Thin-Plate Spline(TPS) 변환을 이용한 키포인트 기반 픽셀 단위 밀집 흐름을 생성한다. TPS 변환은 특정 앵커 픽셀에 기반하여 전체 프레임의 움직임을 근사할 수 있다. 이는 연산 오버헤드를 크게 줄인다. VTO에 필요한 주요 픽셀 30개만 선택하는 것이다. 점수가 높은 순서대로 선택하면, 작은 영역에 키포인트가 밀집되어 중요한 키포인트가 빠질 수 있다. Non-Max Suppression (NMS)를 통해 반복적으로 높은 점수의 픽셀을 선택하고, 그로부터 20픽셀 이내의 키포인트를 제거한다. 광학적 흐름은 context 저장소에 저장된다.
VITOFF Runtime에서는 이전 프레임에서 생성된 VTO 출력을 밀집 변형 흐름을 통해 변형함으로써, 현재 VTO 출력을 생성한다. 변형이 마무리되면, 마스크를 사용하여 원본 이미지 프레임과 사람을 재합성한다.
Warping Error(WE)와 Keypoint Error(KE)로 VITOFF의 트래킹 오류를 포착한다. WE는 변형된 프레임과 기준 프레임 간의 차이를 의미한다. KE는 작은 오류가 시각적으로 중요한 영역에 집중되어 있어 사용자가 VTO 결과를 실패로 인식하는 오류를 고려하여, 사용자 주목도가 높은 키포인트에 초점을 둔다. WE와 KE는 서로 다른 오류를 포착하여 상호 보완적이다.

어떤 면에서 PF-AFN보다 MIRROR가 좋은가
우선 VTO의 품질을 평가하는 기준이 있다. Learned Perceptual Image Patch Similarity(LPIPS)는 합성된 이미지 평가에 널리 활용되는 지표이다. Frechet Video Distance(FVD)는 시간 영역에서의 매끄러움을 포착한다. LPIPS와 FVD가 낮을수록 VTO의 품질이 좋은 것이다.
MIRROR의 각 구성 요소를 하나씩 기준 모델인 PF-AFN에 추가하면서 평가를 진행했다. VITON 데이터셋과 실생활 데이터셋을 바탕으로 LPIPS와 FVD를 측정했다. ROI와 BR을 추가하니 지표 기준으로 VTO 품질이 향상되었다. MO, PI, PL을 추가했을 때도 이미지 및 비디오 품질이 향상되었다. 그러나 DIVTON의 비디오 변환 시간이 PF-AFN에 비해 2배나 길었다. 여기서 VITOFF가 필요함을 알 수 있다.
VITOFF와 DIVTON을 결합하면서 DIVTON의 실행 횟수가 많이 감소하고, 동영상 프레임 중 93.6%가 DNN 없는 경량 트래픽으로 처리되었다. 또한, VITOFF는 DIVTON만 사용할 때보다 지연 시간을 11.6배로 감소시켰다.
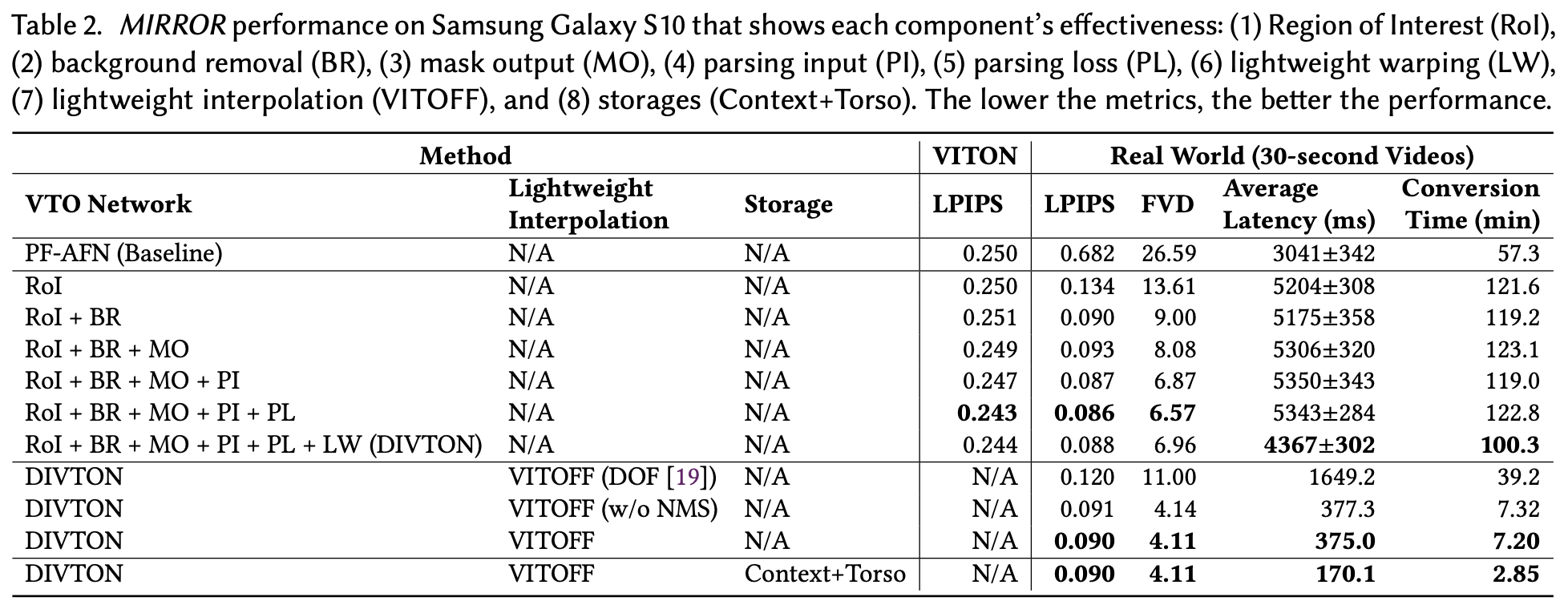
ROI와 BR을 사용했을 때 팔이 구분되지 않는 오류가 있었다. 여기에 MO를 추가하여 배경이 신체 영역을 침범하는 것을 방지하고, PI와 PL을 추가하여 팔을 정확하게 감지하였다. 또한, MIRROR는 시간 영역에서 상관된 위치에 오류를 생성하며, 부드러운 VTO 비디오를 생성했다.

LIP와 ATR 데이터셋은 VITON 테스트 데이터셋에서는 PPP 데이터셋과 비슷한 성능을 보였지만, 실제 데이터셋에서는 DIVTON의 성능을 저하시켰다. 세밀한 인간 분할은 도메인 변화에 취약하고, 큰 범위의 분할은 일반화할 수 있는 VTO를 위한 도메인 불변 특징에 효과적이었다.
MIRROR에서 보완할 부분
1. 실시간 비디오 VTO를 제공한다면 AR과 결합하여 애플리케이션의 확장성이 높아질 것이다.
2. 사용자는 측면과 후면 VTO 결과를 추가로 원할 것이며, 사실적이고 고해상도인 영상 VTO가 필요하다.
3. 의류의 주름처럼 생생한 텍스처와 사용자의 신체에 맞는 의류 사이즈에 대한 연구가 이루어져야 한다.
* 추가 참고자료
- Domain shift: https://www.statlect.com/machine-learning/domain-shift