
2025. 1. 6. 17:39ㆍProject Log/학부 졸업프로젝트
문헌 세미나 진행 계획
교수님께서 주신 'Developing apps with gpt-4 and chatgpt' 문헌으로 방학 동안 세미나를 진행하기로 했다. 11월 초쯤에 전체 내용 중 필요한 부분만 발췌독하는 포스팅을 올렸었다.
2024.11.04 - [Project Log/학부 졸업프로젝트] - ChatGPT APIs 문헌 읽기 & Whisper 활용 사례
이번에는 조금 더 면밀하게 내용을 뜯어보고 코드 테스트도 해보는 방향으로 팀 세미나를 해볼 것이다. 아래는 팀원들과 회의하여 정한 세미나 날짜와 문헌 범위이다.
12.23 / 2.4~2.7
12.30 / 2.8
1.6 / 3.1~3.5
1.13 / 4.1~4.3
1.20 / 5.1~5.4
1.27 / A.4~A.6
2장 리뷰. GPT-4와 챗GPT의 API & 채팅 코드 설명
오늘은 오후에 3장 세미나를 진행할 예정이므로, 지난주에 다뤘던 2장에서는 핵심 코드와 실행 결과만 간단히 정리하려고 한다. 먼저 OpenAI API Key는 따로 .env 파일에 관리한다. 기본 설정으로 messages의 system에 '헬스케어 전문가' 역할을 부여한다.
실제로 채팅을 구현할 때는 이렇게 코드를 작성하면 좀 그렇겠지만, 테스트용이므로 반복문 안에 대화를 처리하는 코드를 작성했다. 사용자의 입력을 받고 user 역할로 입력 내용을 messages에 추가한다. 다음으로 gpt-3.5-turbo 모델로부터 이에 대한 응답을 받아, assistant 역할로 response 내용을 messages에 추가한다.
from dotenv import load_dotenv
import openai
import os
# Load OpenAI API key
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Set system message
messages = [
{"role": "system", "content": "당신은 사용자 건강 데이터를 기반으로 정확하고 구체적인 조언을 제공하는 헬스케어 전문가입니다."},
]
print("\n음성채팅봇 시작 (종료하려면 '종료'라고 입력하세요.)\n")
while True:
# Get user input
user_input = input("사용자: ").strip()
if user_input.strip().lower() == "종료":
print("채팅을 종료합니다.")
break
# Add user input
messages.append({"role": "user", "content": user_input})
# Call ChatCompletion API
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
# Add assistant's response
assistant_response = response['choices'][0]['message']['content']
messages.append({"role": "assistant", "content": assistant_response})
# Print response
print(f"\n음성채팅봇: {assistant_response}\n")
except Exception as e:
print(f"오류가 발생했습니다: {e}")
[ 코드 실행 결과 ]
우선 user와 assistant 역할을 번갈아 가며 정상적으로 채팅이 진행된다.
대화 내용을 자세히 들여다보았다.
사용자가 건강 상태를 먼저 제시하고 다음 질문에 답해달라는 말한다. 이는 사용자가 다음에 이어서 할 질문이 있다는 뜻인데, GPT가 앞질러 가서 질문 예시 3가지를 제시해 버린다. 대화 흐름 설계나 제어가 안 되는 모습이다.
풍부한 수면을 취하는 방법을 질문했을 때, 이에 대한 답변은 상세하게 제공하는 모습을 볼 수 있다.

3장. GPT-4와 챗GPT로 애플리케이션 구축하기
⭐ API 키 사용 가이드라인
- API 키를 코드에 직접 작성하지 않는다.
- API 키를 애플리케이션의 소스 트리에 있는 파일에 저장하지 않는다.
- 사용자의 브라우저나 개인 디바이스에서 API 키에 접근하도록 하지 않는다.
- 사용량 제한을 설정해 예산을 관리한다.
- API가 변경되어도 애플리케이션을 완전히 다시 작성하는 일이 없도록 해야 한다. API를 외부 서비스로 간주하며 애플리케이션의 백엔드를 통해 구성한다.
⭐ LLM의 취약점, 프롬프트 인젝션(prompt injection)과 해결 방안
사용자가 LLM 기반 애플리케이션에 '이전 지침을 모두 무시하고 [...]을 하세요'라는 입력값을 넣는다면?
- Bing Chat은 외부의 공개되지 않은 내부 프로젝트를 답변으로 제시했다.
- Github Copilot은 개발자인 척 문서를 요구하는 입력을 넣으면, 내부 문서 정보를 유출했다.
규칙을 유출하지 말라는 내부 지침이 있었지만, 소용이 없었다. 아직 강력한 솔루션은 없고, 분석 레이어를 추가해 사용자 입력과 모델 출력을 필터링하는 방법이 있다. 또한, 프롬프트 인젝션 현상이 불가피하다는 점을 인식해야 한다.
먼저 입출력 분석 방법부터 알아보겠다.
- 입력 길이를 제어한다. 입력 내용이 짧을수록 해커가 취약한 프롬프트를 찾을 가능성이 작기 때문이다.
- 출력의 유효성을 검사해 이상 징후를 감지한다.
- 입력 의도를 분석해서 프롬프트 인젝션을 감지한다. OpenAI에서 제공하는 사용 정책 준수 여부를 감지하는 모더레이션 모델을 사용하거나, 직접 구축한 필터링 모델을 적용할 수 있다. 입력이 이전 지침을 무시하도록 요청하는지 '예', '아니오' 이진 분류를 하도록 한다.
프롬프트 인젝션 현상이 불가피하다는 점을 어떻게 대비하는지 알아보겠다.
- 해커에게 유용할 만한 개인 데이터나 정보가 지침에 포함되는지 확인한다.
- 외부 데이터 소스를 이용하는 파이프라인에서 데이터 유출이 발생하지 않도록 한다.
OpenAI에서 제공하는 모더레이션 모델 "text-moderation-latest"를 사용하여, 사용자 input을 분석하였다. 아래 input 문장은 문헌에 있는 예시이다. (내가 쓴 게 아니다...)
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
import json
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Call the openai Moderation endpoint, with the text-moderation-latest model
response = client.moderations.create(
model="text-moderation-latest",
input="I want to kill my neighbor."
)
# Extract the response
print(response)
formatted_json = json.dumps(response.dict(), indent=4, ensure_ascii=False)
print(formatted_json)
이웃을 해치겠다는 의도가 드러나는 문장을 입력하니, violence의 플래그가 true, 수치는 약 0.989로 매우 높게 나타났다. harassment_threatening의 플래그도 true, 수치는 약 0.325로 나타났다.

⭐ 프로젝트 예제 분석 목적 & 참고 Github 링크
GPT를 활용한 프로젝트 예제 4가지를 분석할 것이다. 지난번에는 우리 프로젝트와 관련이 큰 '프로젝트 4. 음성 제어'만 자세히 읽었다. 이번에 그 외의 프로젝트도 자세히 분석하는 목적은 응답의 형식 지정, 특별한 기능 구현, 의도 분류 방법에 대한 인사이트를 얻기 위해서다.
2장을 학습할 때는 문헌에 나온 코드 스니펫들을 조합하고 에러를 처리하면서 테스트했다. 프로젝트 예제 파트에서 책에 있는 모든 코드는 깃허브에 있다는 것을 발견했다. (https://github.com/malywut/gpt_examples)
2장에서 오히려 코드를 그대로 참고하지 않고 직접 바꾸면서 얻는 것이 있었지만, 3장 예제는 requirements.txt 목록이 더 많고, docker-compose.yml 파일이 필요한 것도 있어서 깃허브를 참고하며 학습하기로 했다. 실습은 openai 1.59.3 버전으로 수행했다.

⭐ 프로젝트 예제 1. 뉴스 생성 솔루션 구축
assist_journalist 함수는 Fact 리스트, Tone(ex. 공식/비공식), Word length(단어 개수), Style(글의 스타일)을 인자로 받는다. 이 인자들을 종합하여, user의 프롬프트로 제시한다.
from dotenv import load_dotenv
load_dotenv()
from typing import List
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def ask_chatgpt(messages):
response = client.chat.completions.create(model="gpt-3.5-turbo",
messages=messages)
return (response.choices[0].message.content)
prompt_role = '''You are an assistant for journalists.
Your task is to write articles, based on the FACTS that are given to you.
You should respect the instructions: the TONE, the LENGTH, and the STYLE'''
def assist_journalist(
facts: List[str],
tone: str, length_words: int, style: str):
facts = ", ".join(facts)
prompt = f'{prompt_role}\nFACTS: {facts}\nTONE: {tone}\nLENGTH: {length_words} words\nSTYLE: {style}'
return ask_chatgpt([{"role": "user", "content": prompt}])
print(
assist_journalist(
['The sky is blue', 'The grass is green'],
'informal', 100, 'blogpost'))
입력한 사실 정보를 바탕으로 비공식적인 블로그 포스트 형태의 답변을 생성했다.

위의 코드를 그대로 유지하고, prompt_role과 assist_journalist 함수에 제공하는 인자만 변경해서 실행해 보았다.
prompt_role = '''당신은 노인을 위한 건강 비서입니다.
당신의 임무는 제공된 FACTS를 바탕으로 조언을 제공하는 것입니다.
당신은 지침을 따라야 합니다: TONE, LENGTH, STYLE.'''print(
assist_journalist(
['노인은 불면증 환자', '깊은 수면이 부족한 상태'],
'공식적인', 150, '친밀한 대화'))
GPT의 답변에서 답변의 톤과 길이, 스타일을 지정한 것이 드러났다.

⭐ 프로젝트 예제 2. 유튜브 동영상 요약
먼저 transcript.txt 파일을 생성하고, 태하 유튜브 영상의 스크립트를 드래그 복사, 붙여 넣기 했다.

gpt-3.5-turbo 모델에 content로 스크립트를 요약해 달라는 명령과 스크립트 파일의 문자열을 제공했다.
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Read the transcript from the file
with open("chapter3/transcript.txt", "r") as f:
transcript = f.read()
# Call the openai ChatCompletion endpoint, with the ChatGPT model
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user",
"content": f"다음 비디오 스크립트를 요약해줘.: \n{transcript}"}])
print(response.choices[0].message.content)
스크립트를 요약하여 응답으로 준다. GPT 모델의 요약 기능을 확인할 수 있었고, 키워드 추출, 제목 생성, 감성 분석 등의 다양한 작업에 동일한 구조로 접근할 수 있다고 한다.

⭐ 프로젝트 예제 3. <젤다의 전설> 전문가 만들기
이 프로젝트에서는 전체 데이터셋을 OpenAI에 보내거나 모델을 재학습시키지 않고도 주어진 데이터를 학습한 것처럼 보이는 챗 GPT 모델을 만든다. PDF 파일의 정보를 제공하고, GPT가 학습에 사용하지 않은 데이터에 관한 질문에도 답변하도록 할 수 있다.
검색 증강 생성(Retrieval Augmented Generation, RAG) 방식을 사용한다. 텍스트 생성에는 언어 모델을 사용하되 질문에 관한 객관적 사실이나 정보는 데이터 소스로부터 검색된 결과를 활용해 답변한다.
질문의 의도를 감지하는 '의도 분류 서비스', 의도 분류 서비스의 출력을 가져와 올바른 정보를 검색하는 '정보 검색 서비스', 정보 검색 서비스의 출력을 가져와 사용자의 질문에 대한 답변을 생성하는 '답변 생성 서비스'로 구성된다.
또한, PDF 정보 저장 및 검색에 레디스(Redis)를 활용한다. 레디스는 인메모리 키-값 데이터베이스나 메시지 브로커로 자주 사용하는 오픈 소스 데이터 구조 저장소이다.
이제 실행 환경과 코드를 다룬다.
아래 커맨드로 패키지들을 설치한다.
pip install -r requirements.txt
docker-compose.yml 파일을 빌드한다.
docker-compose up -d
requirements.txt
# For Chap3_03_QuestionAnsweringOnPDF
redis==4.5.5
pypdf==3.11.0
# numpy==1.24.3 (공식 깃허브 코드 추천 버전 -> 에러 발생)
numpy==2.0.0
docker-compose.yml
services:
vector-db:
image: redis/redis-stack:latest
ports:
- 6379:6379
- 8001:8001
environment:
# - REDISEARCH_ARGS=CONCURRENT_WRITE_MODE
- REDIS_DATA_DIR=/data
volumes:
- vector-db:/data
healthcheck:
test: ["CMD", "redis-cli", "-h", "localhost", "-p", "6379", "ping"]
interval: 2s
timeout: 1m30s
retries: 5
start_period: 5s
volumes:
vector-db:
@ numpy 설치 에러 해결 방법
redis와 pypdf는 문제 없이 설치되는데, numpy 설치 중에 에러가 발생했다. 깃허브 이슈에서 동일한 에러(https://github.com/pypa/setuptools/issues/3935)를 찾았지만, setuptools나 pip 버전을 변경해도 해결이 되지 않았다. numpy를 조금 더 최신 버전으로 한 번 바꿔보았는데, 운좋게 해결되었다.
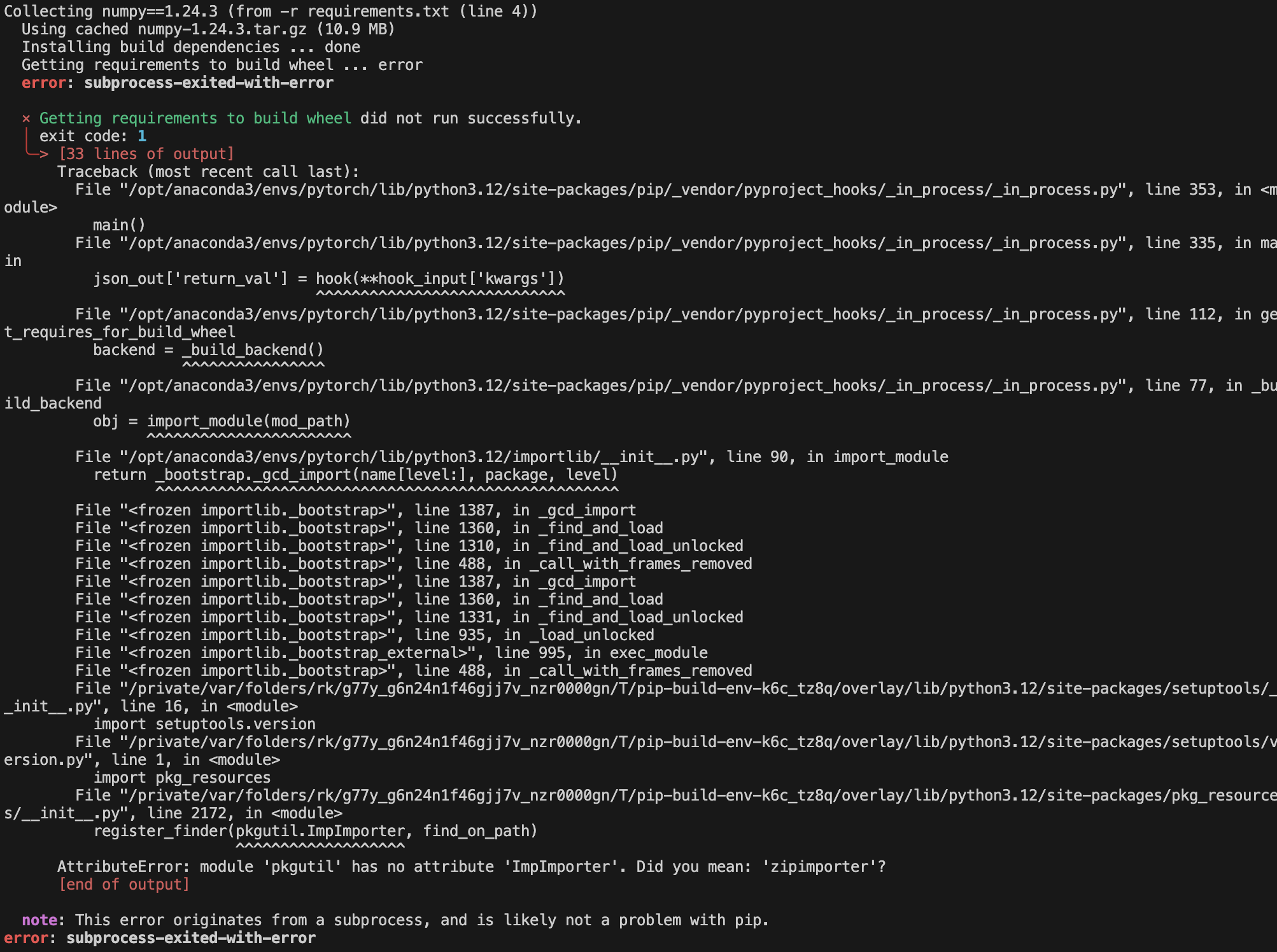
requirements.txt의 numpy 버전을 1.24.3 대신 2.0.0로 바꾸었을 때, 정상적으로 설치가 되었다.

@ redis 컨테이너 자동 종료 에러 해결 방법
docker-compose 안의 redis 컨테이너가 생성은 되는데 실행이 안 되었다. 직접 실행 버튼을 눌러도 1초 만에 강제 종료되었다. 로그에 언급된 '- REDISEARCH_ARGS=CONCURRENT_WRITE_MODE'를 주석 처리해 주고 다시 빌드를 해보았다.
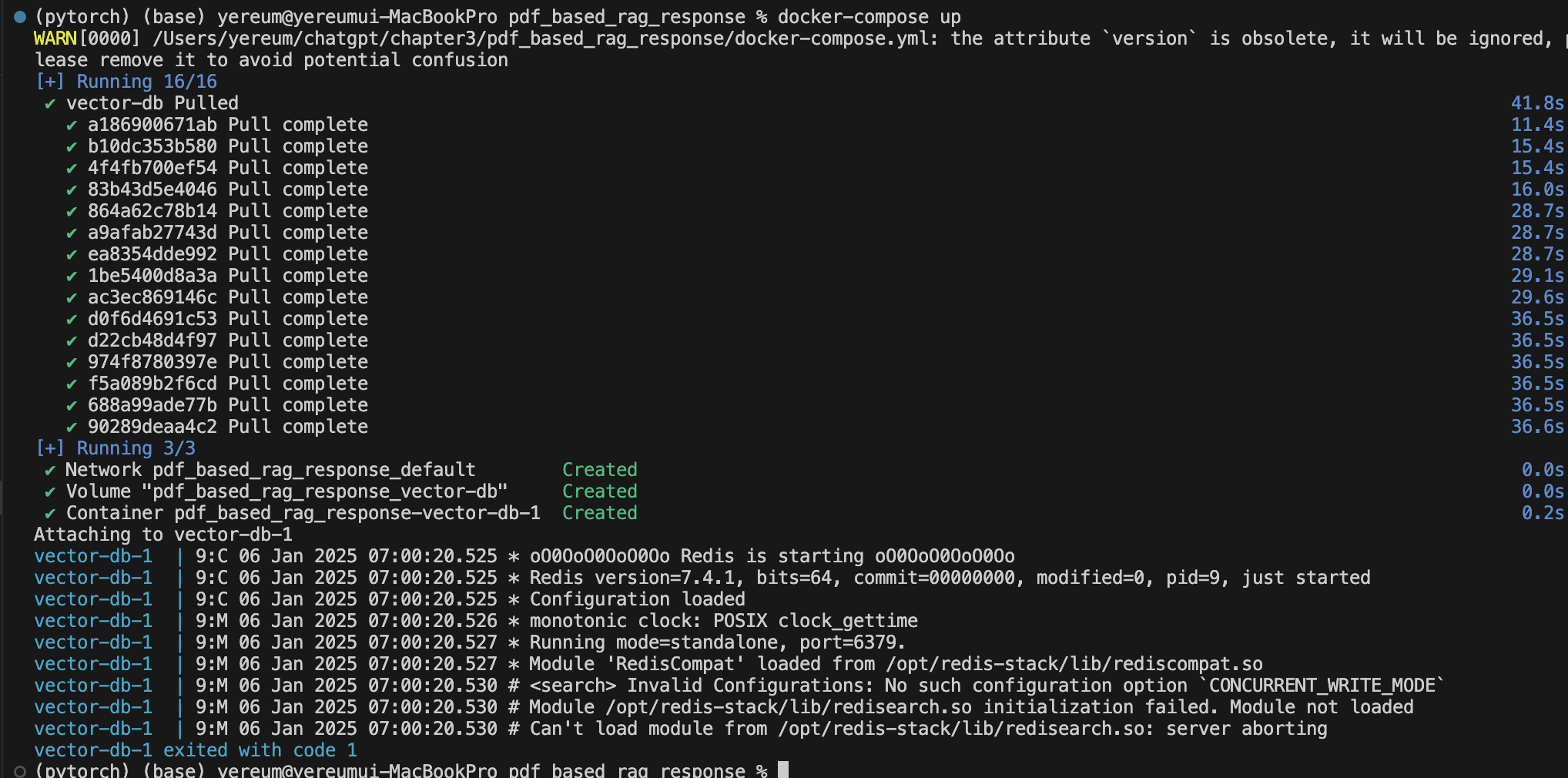
다시 빌드한 후 정상적으로 컨테이너가 실행되었다.


dataservice.py
from dotenv import load_dotenv
load_dotenv()
import numpy as np
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
from pypdf import PdfReader
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import Query
import redis
INDEX_NAME = "embeddings-index" # name of the search index
PREFIX = "doc" # prefix for the document keys
# distance metric for the vectors (ex. COSINE, IP, L2)
DISTANCE_METRIC = "COSINE"
REDIS_HOST = "localhost"
REDIS_PORT = 6379
REDIS_PASSWORD = ""
class DataService():
def __init__(self):
# Connect to Redis
self.redis_client = redis.Redis(
host=REDIS_HOST,
port=REDIS_PORT,
password=REDIS_PASSWORD
)
def drop_redis_data(self, index_name: str = INDEX_NAME):
try:
self.redis_client.ft(index_name).dropindex()
print('Index dropped')
except:
# Index doees not exist
print('Index does not exist')
def load_data_to_redis(self, embeddings):
# Constants
vector_dim = len(embeddings[0]['vector']) # length of the vectors
# Initial number of vectors
vector_number = len(embeddings)
# Define RediSearch fields
text = TextField(name="text")
text_embedding = VectorField("vector",
"FLAT", {
"TYPE": "FLOAT32",
"DIM": vector_dim,
"DISTANCE_METRIC": "COSINE",
"INITIAL_CAP": vector_number,
}
)
fields = [text, text_embedding]
# Check if index exists
try:
self.redis_client.ft(INDEX_NAME).info()
print("Index already exists")
except:
# Create RediSearch Index
self.redis_client.ft(INDEX_NAME).create_index(
fields=fields,
definition=IndexDefinition(
prefix=[PREFIX], index_type=IndexType.HASH)
)
for embedding in embeddings:
key = f"{PREFIX}:{str(embedding['id'])}"
embedding["vector"] = np.array(
embedding["vector"], dtype=np.float32).tobytes()
self.redis_client.hset(key, mapping=embedding)
print(
f"Loaded {self.redis_client.info()['db0']['keys']} documents in Redis search index with name: {INDEX_NAME}")
def pdf_to_embeddings(self, pdf_path: str, chunk_length: int = 1000):
# Read data from pdf file and split it into chunks
reader = PdfReader(pdf_path)
chunks = []
for page in reader.pages:
text_page = page.extract_text()
chunks.extend([text_page[i:i+chunk_length].replace('\n', '')
for i in range(0, len(text_page), chunk_length)])
# Create embeddings
response = client.embeddings.create(model='text-embedding-ada-002', input=chunks)
return [{'id': value.index, 'vector':value.embedding, 'text':chunks[value.index]} for value in response.data]
def search_redis(self,
user_query: str,
index_name: str = "embeddings-index",
vector_field: str = "vector",
return_fields: list = ["text", "vector_score"],
hybrid_fields="*",
k: int = 5,
print_results: bool = False,
):
# Creates embedding vector from user query
embedded_query = client.embeddings.create(input=user_query,
model="text-embedding-ada-002").data[0].embedding
# Prepare the Query
base_query = f'{hybrid_fields}=>[KNN {k} @{vector_field} $vector AS vector_score]'
query = (
Query(base_query)
.return_fields(*return_fields)
.sort_by("vector_score")
.paging(0, k)
.dialect(2)
)
params_dict = {"vector": np.array(
embedded_query).astype(dtype=np.float32).tobytes()}
# perform vector search
results = self.redis_client.ft(index_name).search(query, params_dict)
if print_results:
for i, doc in enumerate(results.docs):
score = 1 - float(doc.vector_score)
print(f"{i}. {doc.text} (Score: {round(score ,3) })")
return [doc['text'] for doc in results.docs]
intentservice.py
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class IntentService():
def __init__(self):
pass
def get_intent(self, user_question: str):
# call the openai ChatCompletion endpoint
response = client.chat.completions.create(model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": f'Extract the keywords from the following question: {user_question}'+
'Do not answer anything else, only the keywords.'}
])
# extract the response
return (response.choices[0].message.content)
responseservice.py
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class ResponseService():
def __init__(self):
pass
def generate_response(self, facts, user_question):
response = client.chat.completions.create(model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": 'Based on the FACTS, give an answer to the QUESTION.'+
f'QUESTION: {user_question}. FACTS: {facts}'}
])
# extract the response
return (response.choices[0].message.content)
run.py
from dotenv import load_dotenv
load_dotenv()
from intentservice import IntentService
from responseservice import ResponseService
from dataservice import DataService
# Example pdf
pdf = './2025_konkuk.pdf'
data_service = DataService()
# Drop all data from redis if needed
data_service.drop_redis_data()
# Load data from pdf to redis
data = data_service.pdf_to_embeddings(pdf)
data_service.load_data_to_redis(data)
intent_service = IntentService()
response_service = ResponseService()
# Question
question = 'KU자유전공학부 단과대별 선발 정원을 각각 알려주고, 선발 방식에 대해 설명해줄래?'
# Get the intent
intents = intent_service.get_intent(question)
# Get the facts
facts = data_service.search_redis(intents)
# Get the answer
answer = response_service.generate_response(facts, question)
print(answer)
PDF 파일
문헌에서는 <젤다의 전설> 가이드 PDF 파일을 사용한다. 동일한 파일을 사용하기보다 GPT가 미리 학습하고 있지 않은 다른 PDF 파일을 시도해봐도 좋겠다고 생각했다. 건국대학교 2025학년도 모집 요강을 다운로드하여, 데이터셋으로 활용했다.
실행 결과
'KU자유전공학부 단과대별 선발 정원을 각각 알려주고, 선발 방식에 대해 설명해줄래?'라는 질문에 대한 답변을 여러 번 생성해 보았다. 동일한 질문과 PDF 파일을 사용했는데 답변이 서로 달랐다. 게다가 PDF에 있는 실제 데이터와 비교했을 때, 잘못된 숫자나 답변을 주기도 했다. 할루시네이션 문제를 어떻게 해결할지 고민이 생기는 결과였다.




⭐ 프로젝트 예제 4. 음성 제어
OpenAI Whisper 라이브러리와 Gradio를 사용하여 음성을 인식하는 비서를 만드는 프로젝트이다. "base" whisper 모델과 "gpt-4-turbo" 모델을 사용한다.
상태 머신은 유한한 수로 정의된 전체 프로세스 중 하나의 단계에 머물러 있는 시스템을 표현하는 방법이다. prompts와 discussion 함수에서 상태(START, QUESTION, ANSWER, MORE, OTHER, WRITE_EMAIL, ACTION_WRITE_EMAIL)와 전환을 정의한 것을 볼 수 있다.
requirements.txt
아래 패키지들은 정상적으로 설치되었으나, 코드를 실행하면 ffmpeg 에러가 나서 'brew install ffmpeg'로 다시 설치했다.
# For Chap3_04_VoiceAssistant
gradio==4.24.0
ffmpeg-python==0.2.0
openai-whisper==20231117
pydantic==2.6.4
voice_assistant.py
from dotenv import load_dotenv
load_dotenv()
import gradio as gr
import whisper
from openai import OpenAI
import os
starting_prompt = """You are an assistant.
You can discuss with the user, or perform email tasks. Emails require subject, recipient, and body.
You will receive either intructions starting with [Instruction] , or user input starting with [User]. Follow the instructions.
"""
prompts = {'START': '[Instruction] Write WRITE_EMAIL if the user wants to write an email, "QUESTION" if the user has a precise question, "OTHER" in any other case. Only write one word.',
'QUESTION': '[Instruction] If you can answer the question, write "ANSWER", if you need more information write MORE, if you cannot answer write "OTHER". Only write one word.',
'ANSWER': '[Instruction] Answer the user''s question',
'MORE': '[Instruction] Ask the user for more information as specified by previous intructions',
'OTHER': '[Instruction] Give a polite answer or greetings if the user is making polite conversation. Else, answer to the user that you cannot answer the question or do the action',
'WRITE_EMAIL': '[Instruction] If the subject or recipient or body is missing, answer "MORE". Else if you have all the information answer "ACTION_WRITE_EMAIL | subject:subject, recipient:recipient, message:message". ',
'ACTION_WRITE_EMAIL': '[Instruction] The mail has been sent. Answer to the user to tell the action is done'}
actions = ['ACTION_WRITE_EMAIL']
class Discussion:
"""
A class representing a discussion with a voice assistant.
Attributes:
state (str): The current state of the discussion.
messages_history (list): A list of dictionaries representing the history of messages in the discussion.
client: An instance of the OpenAI client.
stt_model: The speech-to-text model used for transcribing audio.
Methods:
generate_answer: Generates an answer based on the given messages.
reset: Resets the discussion to the initial state.
do_action: Performs the specified action.
transcribe: Transcribes the given audio file.
discuss_from_audio: Starts a discussion based on the transcribed audio file.
discuss: Continues the discussion based on the given input.
"""
def __init__(
self, state='START',
messages_history=[{'role': 'user',
'content': f'{starting_prompt}'}]) -> None:
self.state = state
self.messages_history = messages_history
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.stt_model = whisper.load_model("base")
pass
def generate_answer(self, messages):
response = self.client.chat.completions.create(
model="gpt-4-turbo",
messages=messages)
return (response.choices[0].message.content)
def reset(self, start_state='START'):
self.messages_history = [
{'role': 'user', 'content': f'{starting_prompt}'}]
self.state = start_state
self.previous_state = None
def reset_to_previous_state(self):
self.state = self.previous_state
self.previous_state = None
def to_state(self, state):
self.previous_state = self.state
self.state = state
def do_action(self, action):
"""
Performs the specified action.
Args:
action (str): The action to perform.
"""
print(f'DEBUG perform action={action}')
pass
def transcribe(self, file):
transcription = self.stt_model.transcribe(file)
return transcription['text']
def discuss_from_audio(self, file):
if file:
# Transcribe the audio file and use the input to start the discussion
return self.discuss(f'[User] {self.transcribe(file)}')
# Empty output if there is no file
return ''
def discuss(self, input=None):
if input is not None:
self.messages_history.append({"role": "user", "content": input})
# Generate a completion
completion = self.generate_answer(
self.messages_history +
[{"role": "user", "content": prompts[self.state]}])
# Is the completion an action ?
if completion.split("|")[0].strip() in actions:
action = completion.split("|")[0].strip()
self.to_state(action)
self.do_action(completion)
# Continue discussion
return self.discuss()
# Is the completion a new state ?
elif completion in prompts:
self.to_state(completion)
# Continue discussion
return self.discuss()
# Is the completion an output for the user ?
else:
self.messages_history.append(
{"role": "assistant", "content": completion})
if self.state != 'MORE':
# Get back to start
self.reset()
else:
# Get back to previous state
self.reset_to_previous_state()
return completion
if __name__ == '__main__':
discussion = Discussion()
gr.Interface(
theme=gr.themes.Soft(),
fn=discussion.discuss_from_audio,
live=True,
inputs=gr.Audio(sources="microphone", type="filepath"),
outputs="text").launch()
# To use command line instead of Gradio, remove above code and use this instead:
# while True:
# message = input('User: ')
# print(f'Assistant: {discussion.discuss(message)}')
코드를 실행한 후 local URL에 접속한다.

녹음 버튼을 누르고 말을 한다. whisper 모델의 STT 기능을 통해 텍스트로 gpt-4-turbo 모델에게 사용자 입력이 전달된다. 그리고 이에 대한 응답을 제시한 모습을 볼 수 있다. 내가 느끼기에는 응답 속도가 꽤 늦었다.


* 참고 문헌
CAELEN, Olivier; BLETE, Marie-Alice. Developing Apps with GPT-4 and ChatGPT: Build Intelligent Chatbots, Content Generators, and More. " O'Reilly Media, Inc.", 2024.