
2025. 1. 13. 18:29ㆍProject Log/학부 졸업프로젝트
이번 주 문헌 세미나 목표
- 모델 버전을 바꾸어 3장에서 있었던 이슈를 해결한다.
- 4장 내용을 바탕으로 프롬프트 엔지니어링에 따라 응답 결과가 어떻게 달라지는지 분석하고, 기본적인 파인튜닝 실습을 진행한다.
3장 학습 내용 보완
지난주 'gpt-3.5-turbo'를 사용하고 동일한 질문에 대한 여러 개의 응답을 비교했을 때, 일부 잘못된 정보를 포함하거나 답변 양식의 차이가 큰 것을 발견했다. 교수님께서 상위 레벨의 모델로도 테스트해 보라고 하셔서 간단히 진행을 해보았다.
https://yr-dev.tistory.com/entry/문헌-세미나-3장-GPT-4와-챗GPT로-애플리케이션-구축하기-feat-2장-간단한-리뷰-포함
프로젝트 예제 3 코드 중 intentservice.py와 responseservice.py의 'gpt-3.5-turbo' 모델을 'gpt-4o' 모델로 수정하였다. dataservice.py에 있는 'text-embedding-ada-002' 모델은 그대로 유지하였다.
지난번에 선발 인원에서 PDF 정보와는 다른 잘못된 정보를 표시했었는데, 최신 모델을 사용하니 정확한 숫자를 표시했다.


한 번 더 실행했을 때도 선발 인원을 정확히 표시했고, 전형 일정도 오류가 없었다. 단 일부 전형을 제외하고 일정을 알려주는 아쉬운 면이 있기는 했다. 그래도 이전의 문제가 해결된 것을 보면, 최신 모델을 사용했을 때 정확도가 더 높아진다.

4장. 프롬프트 엔지니어링
프롬프트 엔지니어링(Prompt engineering)은 LLM이 최대한 적합한 출력을 생성할 수 있도록, 최적의 입력 형태와 사례를 개발하는 데 중점을 둔다. temperature, top_p, max_token과 같이 파라미터를 사용하면 동일한 프롬프트로 상당히 다른 결과를 얻을 수도 있다.
프롬프트에 일반적으로 역할, 컨텍스트, 작업 요소를 정의한다.
(역할) You are a nutritionist designing healthy diets for high-performance athletes.
You take into account the nutrition needed for a good recovery.
(컨텍스트) I do 2 hours of sport a day.
I am vegetarian, and I don't like green vegetables.
I am conscientious about eating healthily.
(작업) Based on your expertise, give me a suggestion for a main course for today's lunch.
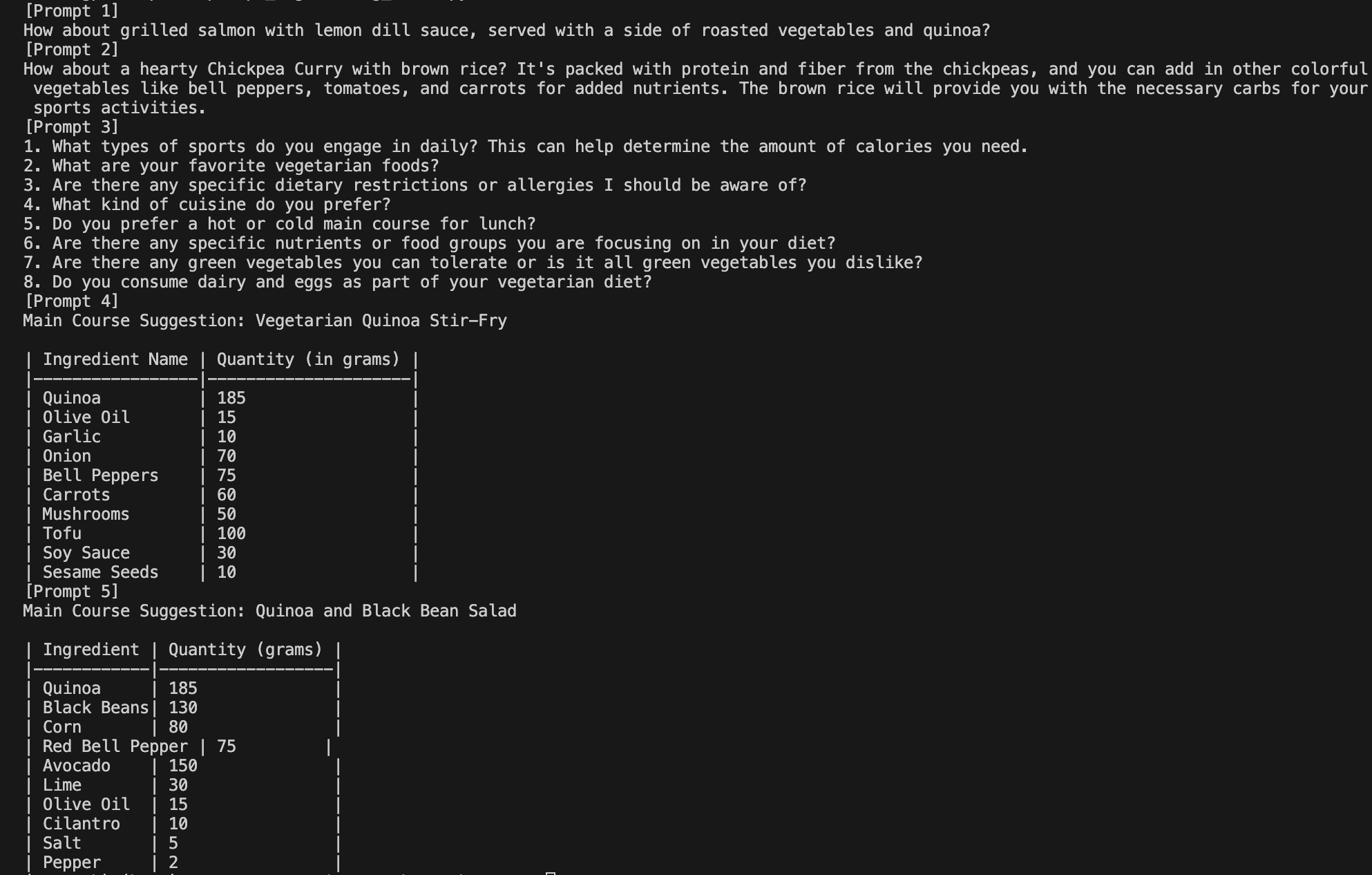
prompt1부터 prompt5까지를 실행시켜서 결과를 비교해 보았다. chat_completion 함수를 여러 번 직접 호출하기에 지저분 했다. 그래서 globals()를 추가하여 prompt{번호} 변수명을 동적으로 사용했다.
각 프롬프트의 특징은 아래와 같다.
- prompt1: 컨텍스트 세부 사항이 거의 없이 점심 메뉴를 추천하라는 Task를 요청한다.
- prompt2: 운동 시간, 채식주의자 유무, 관심 식단 등의 컨텍스트 세부 사항을 제공하고 Task를 요청한다.
- prompt3: Task에 답변 요청 대신, 완성도를 높이는 컨텍스트가 무엇인지 질문하도록 한다.
- prompt4: Task에 메인 요리의 재료와 1인당 그램 수를 표에 대한 요청을 추가한다.
- prompt5: Role, Context, Task를 모두 상세하게 제공했다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def chat_completion(prompt, model="gpt-4", temperature=0):
res = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content":prompt}],
temperature=temperature,
)
print(res.choices[0].message.content)
# Simple question
prompt1 = "Give me a suggestion for the main course for today's lunch."
# Context + Task
prompt2 = """
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green
vegetables. I am conscientious about eating healthily.
Task: Give me a suggestion for a main course for today's lunch."""
# Context + Task(Request additional questions)
prompt3 = """
Context: I do 2 hours of sport a day. I am vegetarian and I don't like green
vegetables. I am very careful to eat healthily.
Task: Give me a suggestion for a main course for today's lunch?
Do not perform the requested task! Instead, can you ask me questions about the
context so that when I answer, you can perform the requested task more
efficiently?
"""
# Context + Task(Request table)
prompt4 = """
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green
vegetables. I am conscientious about eating healthily.
Task: Give me a suggestion for a main course for today's lunch.
With this suggestion, I also want a table with two columns where each row
contains an ingredient from the main course.
The first column in the table is the name of the ingredient.
The second column of the table is the number of grams of that ingredient needed
for one person. Do not give the recipe for preparing the main course.
"""
# Role + Context + Task
prompt5 = """
Role: You are a nutritionist designing healthy diets for high-performance athletes. You take into account the nutrition needed for a good recovery.
Context: I do 2 hours of sport a day. I am vegetarian, and I don't like green vegetables. I am conscientious about eating healthily.
Task: Based on your expertise defined in your role. Give me a suggestion for a main course for today's lunch.
With this suggestion, I also want a table with two columns where each row in the table contains an ingredient from the main course.
The first column in the table is the name of the ingredient.
The second column of the table is the number of grams of that ingredient needed for one person.
Do not give the recipe for preparing the main course.
"""
for i in range(5):
# globals(): Converts all global variables into a dictionary format
# It enables dynamic use of variable names.
prompt = globals()[f"prompt{i+1}"]
print(f"[Prompt {i+1}]")
chat_completion(prompt)
[실행 결과]
프롬프트 작성 방식에 따라, 응답 형태에 매우 큰 차이가 있다.
Zero-shot-CoT: 수학 문제의 단계별 추론
GPT에 수학 문제 풀이를 맡기면, 다른 작업에 비해 오답을 많이 생성한다고 느꼈었다. 문헌에서도 복잡한 수학 문제를 잘 해결하지 못한다는 이야기가 나온다. 그런데 프롬프트 끝에 'Let's think step by step'을 추가하면 모델의 추론 문제 해결력이 향상된다고 한다.
이는 제로샷-CoT 방식으로, 'Large Language Models Are Zero-Shot Reasoners(2022)'라는 논문에서 제시하였다. 제로샷은 모델이 추론을 수행할 때 작업별 예시에 의존하지 않고 일반적인 학습을 기반으로 새로운 작업을 처리할 준비가 됐다는 의미이다. Chain of Thought(CoT)는 모델이 단계별 추론을 모방하도록 유도하는 프롬프트 사용 기법이다. CoT는 GPT 모델의 정확도를 크게 향상한다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def chat_completion(prompt, model="gpt-4", temperature=0):
res = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content":prompt}],
temperature=temperature,
)
print(res.choices[0].message.content)
basic_prompt = "How much is 369 * 1235?"
cot_prompt = "How much is 369 * 1235 ? Let's think step by step."
print("[Basic prompt]\n")
chat_completion(basic_prompt)
print("\n[Cot prompt]\n")
chat_completion(cot_prompt)
[실행 결과]
문제의 답은 455,715이다. 실행 결과 1은 369에 200 말고 2000을 곱하면서 계산이 틀어졌고, 369에 1000을 곱하지 않았다. 실행 결과 2는 369에 1000을 곱하는 연산을 수행하지 않은 채 값들을 더해버렸다. 문헌 결과는 CoT 방식만 정답을 도출했다. 나는 5번 정도 실행했는데, 단계별 추론을 요청한 것과 그렇지 않은 것 모두 오답이 나왔다.


chat_completion 함수에서 "gpt-4" 모델 대신 가장 최신 모델인 "gpt-4o"로 변경하여, 코드를 다시 실행해 보았다. CoT 방식만 455,715라는 정답을 출력했다. gpt-4와 gpt-4o는 수학적 추론 능력에 차이가 있는 것으로 보인다.

퓨샷 러닝 (Few-shot learning)
퓨샷 러닝은 프롬프트에서 몇 개의 예시만으로 일반화해 가치 있는 결과를 도출하는 LLM의 능력이다. 아래 예제에서는 LLM에 특정 단어를 이모티콘으로 변환하도록 요청한다. 프롬프트로 담아내기 어렵지만 퓨샷 러닝으로는 쉽게 배울 수 있다. 원하는 출력에 관한 입력 예시를 제공하며, 마지막 줄에 완성을 원하는 프롬프트를 입력하는 형식이다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def chat_completion(prompt, model="gpt-4", temperature=0):
res = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content":prompt}],
temperature=temperature,
)
print(res.choices[0].message.content)
prompt = """
I go home --> 😊 go 🏠
my dog is sad --> my 🐶 is 😞
I run fast --> 😊 run ⚡
I love my wife --> 😊 ❤️ my wife
the girl plays with the ball --> the 👧 🎮 with the 🏀
The boy writes a letter to a girl -->
"""
chat_completion(prompt)
[실행 결과]
프롬프트로 제공한 이모티콘 변환 예시 몇 개만으로 마지막 문자열을 이모티콘으로 변환했다. 퓨샷 러닝이 무엇인지 감을 잡을 수 있었다.

원샷 러닝 (One-shot learning)
모델이 작업을 실행하는 데 도움이 되는 예시를 단 하나만 제공하며, 더 간단한 작업이나 LLM이 이미 해당 주제의 배경지식이 풍부할 때 효과적이다. 장점은 단순성, 신속한 프롬프트 생성, 토큰 수 추가가 크지 않음에 따른 API 비용 절감이다.
프롬프트 효과 향상
1. 모델에 더 많이 질문하도록 지시한다.
프롬프트를 종료할 때 모델에 질문을 이해했는지 물어보고, 이해하지 못했다면 모르는 부분을 질문하도록 한다.
Did you understand my request clearly? If you do not fully understand my request, ask
me questions about the context so that when I answer, you can perform the requested
task more efficiently.
2. 출력 서식을 지정한다.
JSON 출력을 원할 때 모델은 JSON 블록 앞뒤에 출력을 작성하는 경향이 있다. 'The output must be accepted by json.loads'라는 프롬프트를 추가하면 더 잘 작동한다.
3. 지침을 반복한다.
동일한 지침을 다른 방식으로 여러 번 추가하면 프롬프트가 길 때 좋은 결과를 얻는다.
4. 네거티브 프롬프트를 사용한다.
네거티브 프롬프트는 출력에 표시하고 싶지 않은 내용을 지정한다. 특정 유형의 응답을 걸러내는 제약 조건, 가이드라인 역할을 한다.
Do not add anything before or after the json text
5. 길이를 제한한다.
한 단어, 열 문장과 같이 길이 제한 조건을 추가하는 것이 좋다.
LENGTH: 100 wordsOnly answer one word.
프롬프트 엔지니어링 온라인 자료:
https://github.com/f/awesome-chatgpt-prompts
GitHub - f/awesome-chatgpt-prompts: This repo includes ChatGPT prompt curation to use ChatGPT and other LLM tools better.
This repo includes ChatGPT prompt curation to use ChatGPT and other LLM tools better. - f/awesome-chatgpt-prompts
github.com
파인 튜닝
회사에서 사용할 이메일 응답 생성기를 만든다면?
방법 1️⃣ 프롬프트 엔지니어링 기법으로 모델이 원하는 텍스트를 출력하도록 강제한다.
방법 2️⃣ 기존 모델을 파인튜닝 한다.
방법 1은 위에서 다루었으니, 이제 방법 2에 대해 자세히 알아보겠다.
특정 비즈니스 도메인의 데이터, 고객 문의, 문의에 대한 응답이 포함된 대량의 이메일 데이터로 기존 모델을 파인 튜닝할 것이다. 파인 튜닝의 목표는 조정된 새 모델이 특정 도메인에서 기존 GPT 모델보다 더 나은 예측을 하는 것이다. ⭐ 새 모델은 OpenAI 서버에 있으므로 로컬에서 접근할 수 없고 OpenAI API를 활용해야 한다.
| 파인 튜닝 | 퓨샷 러닝 |
| - 모델의 내부 파라미터를 업데이트함. - 특정 도메인에 맞는 모델을 생성해 주어진 작업에 더 정확하고 맥락에 맞는 결과를 얻을 수 있음. |
- 제한된 개수의 예시를 제공하고, 모델은 예시를 기반으로 원하는 결과를 생성하도록 함. 내부 파라미터는 수정되지 않음. - 모델 자체를 다시 학습시키지 않아도 되므로 유연하고 데이터 및 비용 효율적인 접근 방식임. |
이제부터 OpenAI API를 활용하여 모델을 파인 튜닝하는 방법을 알아보겠다.
JSONL 파일로 변환
LLM을 업데이트하려면 데이터셋이 프롬프트-완성 쌍으로 구성되고, JSONL 파일 형태로 있어야 한다. OpenAI는 JSONL 훈련 파일을 생성하는 도구를 제공한다. CSV, TSV, XLSX, JSON, JSONL을 입력으로 받고, 프롬프트 완성 열/키를 포함한 JSONL 파일을 출력한다.
아래 커맨드를 실행하여 CSV 파일을 JSONL 파일로 변환했다.
openai tools fine_tunes.prepare_data -f prompt_completion.csv
커맨드에 -q 옵션을 추가하면 모든 제안을 자동으로 수락할 수 있다.

입력한 CSV 파일과 JSONL 파일은 다음과 같다. 상위 행 일부만 캡처한 것이다. CSV 파일은 공식 깃허브 링크에서 다운로드했다. (https://github.com/malywut/gpt_examples/tree/main/Chap4_02_FineTuning)


데이터 사용 가능 여부 판별
데이터셋을 OpenAI 서버에 업로드해야 한다. 아래 코드에서 file과 purpose 파라미터는 필수이다. purpose를 fine-tune으로 설정하면 다운로드한 파일 형식의 유효성을 검사해 파인 튜닝할 수 있다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def upload_file(upload_file):
# Upload file
client.files.create(
file=open(upload_file, "rb"),
purpose="fine-tune")
def delete_file(file):
# Delete file
client.files.delete(file)
def file_list():
# Show uploaded file list
file_list = client.files.list()
print(file_list)
# Upload file & Show a list of files
upload_file("./chapter4/fine_tuning/prompt_completion_prepared.jsonl")
file_list()
# Delete file
delete_file("file-A43QCWmeWp2hQe46HtS24q")
file_list()
1. 파일 업로드 / 삭제 / 목록 확인하기
JSONL 파일을 업로드하고, 업로드한 파일 목록을 출력하면 다음과 같이 나온다. 파일 ID를 확인할 수 있다.

파일 ID를 복사하여 client.files.delete에 문자열 인자로 전달하고, 업로드한 파일 목록을 출력하면 방금 전 파일이 삭제된 것을 볼 수 있다.

파인 튜닝된 모델 만들기
파일 업로드에서와 비슷하게 파인 튜닝 모델 생성, 작업 목록 확인, 작업 취소 함수가 있다.
client.fine_tuning.jobs.create() 함수의 주요 파라미터의 의미를 알아둘 필요가 있다.
- training_file: 유일한 필수 파라미터이다. 업로드한 파일의 file_id를 입력하며, 키가 prompt와 completion인 JSONL 파일로 지정해야 한다.
- model: 파인 튜닝에 사용할 기본 모델을 지정한다. ada, babbage, curie, davinci 또는 이전에 튜닝된 모델을 선택할 수 있고, 기본 모델은 curie이다.
- validation_file: 검증 데이터와 함께 업로드한 파일의 file_id를 입력한다. 파인 튜닝 중에 주기적으로 유효성 검사 지표를 생성하는 데 사용된다.
- suffix: 모델 이름에 추가되는 사용자 지정 문자열이다. (최대 40자)
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Fine-tuning
def create_fine_tuned_model():
client.fine_tuning.jobs.create(
training_file="file-Xj1DNTaon8Rphf3j2dYo8C",
model="curie",
# validation_file="",
suffix="store-data"
)
# ShowList of Fine-tuning task
def fined_tuned_list():
fined_tuned_list = client.fine_tuning.jobs.list()
print(fined_tuned_list)
# Stop Fine-tuning task
def stop_fine_tuning(finetuing_id):
client.fine_tuning.jobs.cancel(finetuing_id)
# Delete Fine-tuned model
def delete_fine_tuning(finetuing_id):
client.models.delete(finetuing_id)
# Fine-tuning & Show List of Fine-tuning task
create_fine_tuned_model()
fined_tuned_list()
# Stop Fine-tuning task & Show List of Fine-tuning task
stop_fine_tuning("")
fined_tuned_list()
# Delete Fine-tuned model & Show List of Fine-tuning task
delete_fine_tuning("")
fined_tuned_list()
gpt-3.5-turbo는 prompt-completion이 아닌, chat-formatted data가 필요하다는 에러 메시지가 나왔다.

사이트에 들어가 보면 파인 튜닝을 위한 데이터 포맷이 role과 content가 포함된 Chat 형식으로 변경되었다고 한다. 파일 생성부터 다시 바꿔야겠다는 생각이 들었다.
- Data format for fine-tuning 3.5 Turbo?:
https://community.openai.com/t/data-format-for-fine-tuning-3-5-turbo/327746
- OpenAI docs: Fine-tuning:
https://platform.openai.com/docs/guides/fine-tuning

Message(Role-Content) 채팅 형식 데이터 생성 및 파인 튜닝
이메일 마케팅 대행사를 위한 텍스트 생성 도구를 만드는 예제이다. 데모 목적으로 GPT 모델을 사용하여 파인 튜닝용 데이터를 합성할 것이다. 문헌에 있는 코드는 Prompt-Completion 형식으로 데이터를 추가한다. 이 부분을 Message(Role-Content) 형식으로 수정하였다.
로그를 출력하며, JSONL 파일을 생성했다. (CSV 파일을 생성해서 JSONL 파일로 변환하지 않고 바로 JSONL을 생성했다. 파일을 생성했더니, OpenAI 충전 잔액이 $2.99에서 $2.97로 줄었다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
import pandas as pd
import json
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def chat_completion(prompt, model="gpt-4", temperature=0):
res = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
)
return res.choices[0].message.content.strip()
l_sector = ['Grocery Stores', 'Restaurants', 'Fast Food Restaurants', 'Pharmacies', 'Service Stations (Fuel)', 'Electronics Stores']
l_city = ['Brussels', 'Paris', 'Berlin']
l_size = ['small', 'medium', 'large']
f_prompt = """
Role: You are an expert content writer with extensive direct marketing experience. You have strong writing skills, creativity, adaptability to different tones and styles, and a deep understanding of audience needs and preferences for effective direct campaigns.
Context: You have to write a short message in maximum 2 sentences for a direct marketing campaign to sell a new e-commerce payment service to stores.
The target stores have the three following characteristics:
- The sector of activity: {sector}
- The city where the stores are located: {city}
- The size of the stores: {size}
Task: Write the short message for the direct marketing campaign. To write this message, use your skills defined in your role! It is very important that the messages you produce take into account the product you want to sell and the characteristics of the store you want to write to.
"""
data = []
for sector in l_sector:
for city in l_city:
for size in l_size:
for i in range(3):
prompt = f_prompt.format(sector=sector, city=city, size=size)
response_txt = chat_completion(prompt, model='gpt-3.5-turbo', temperature=1)
message = {
"messages": [
{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."},
{"role": "user", "content": prompt.strip()},
{"role": "assistant", "content": response_txt.strip()}
]
}
data.append(message)
print(message) # LOG
jsonl_filename = "role_content_marketing_data.jsonl"
with open(jsonl_filename, "w", encoding="utf-8") as jsonl_file:
for entry in data:
jsonl_file.write(json.dumps(entry, ensure_ascii=False) + "\n")
print(f"JSONL 파일 생성 완료: {jsonl_filename}")
파일 업로드 코드의 파일명만 바꾸어 실행했다.

파인 튜닝 모델 생성 코드의 학습 파일 ID, GPT 모델(gpt-3.5-turbo), suffix만 간단히 변경하고 실행했다. 아까와 달리 Error가 발생하지 않았다. status 값을 보면 현재 학습 진행 상태를 알 수 있다. status가 validation_files에 있다면 파일이 유효한지 검증하는 단계이고, running에 있다면 학습이 진행 중인 것이다.


학습이 성공적으로 완료되면 status에 'succeeded'가 나온다. OpenAI 충전 잔액이 $2.97에서 $2.07로 줄었다.

파인 튜닝된 모델 테스트
OpenAI Playground에서 모델을 쉽게 테스트 할 수 있다. 인터페이스 오른쪽 드롭다운 목록 > FINE-TUNES에서 만든 모델을 선택하면 된다. 'Hotel, New York, small ->'만 입력 프롬프트로 넣어도, Assistant가 뉴욕의 소규모 호텔에 대한 광고를 생성했다.

API로 파인 튜닝 모델 사용하기
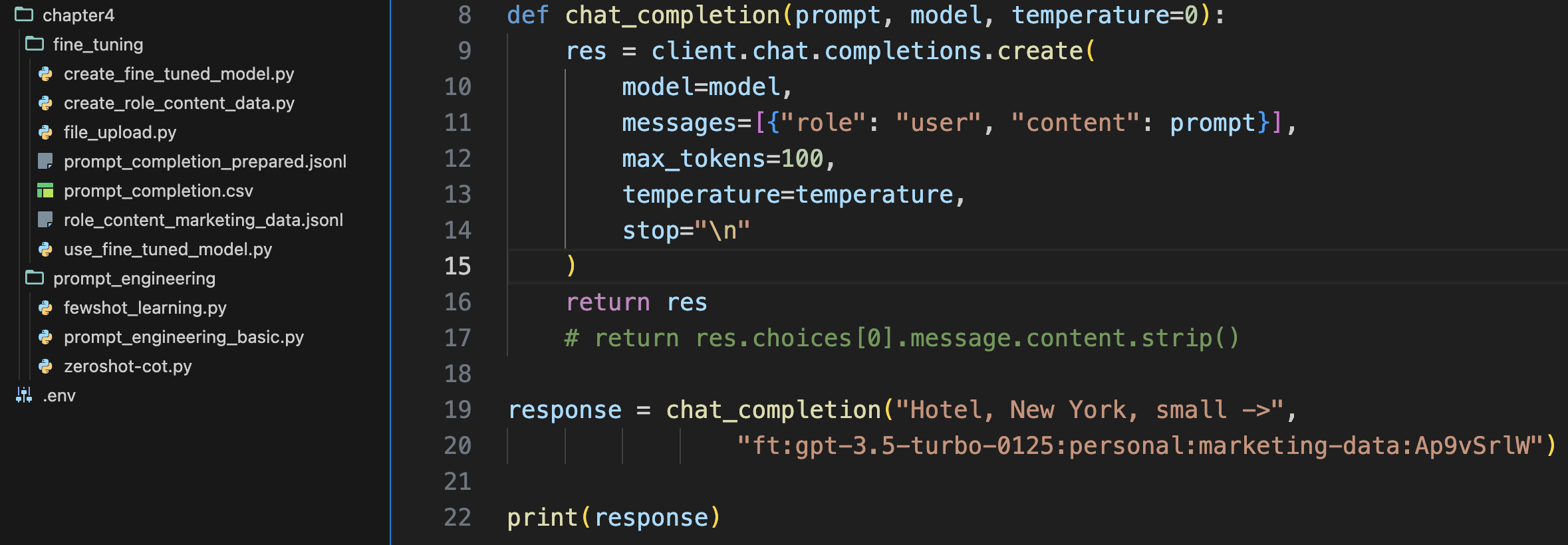
chat_completion 함수를 호출할 때 입력 프롬프트와 파인 튜닝한 모델명을 전달하였다.
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def chat_completion(prompt, model, temperature=0):
res = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=100,
temperature=temperature,
stop="\n"
)
return res
# return res.choices[0].message.content.strip()
response = chat_completion("Hotel, New York, small ->",
"ft:gpt-3.5-turbo-0125:personal:marketing-data:Ap9vSrlW")
print(response)
파인 튜닝한 대로 뉴욕의 소규모 호텔에 대한 광고가 응답으로 제시되었다.

느낀 점
- 문헌에 있는 대로 prompt-completion 형태 데이터를 만들었다가 에러를 겪었다. 빠르게 변화하고 더 편리하게 업데이트되는 기술인만큼 공식 문서의 최신 내용을 미리 확인하는 게 중요하다고 느꼈다.
- 파인 튜닝 과정에서 모든 작업을 OpenAI 서버와 상호작용을 하며 유료 기능을 활용해야 했다. 데이터 형식에 주의해서 코드를 작성해야 불필요한 시간 소요와 비용 손실을 줄일 수 있을 것이다.
* 참고 문헌
CAELEN, Olivier; BLETE, Marie-Alice. Developing Apps with GPT-4 and ChatGPT: Build Intelligent Chatbots, Content Generators, and More. " O'Reilly Media, Inc.", 2024.