
2024. 9. 8. 16:02ㆍArtificial Intelligence/모두를 위한 딥러닝 (PyTorch)
MNIST Introduction 이론 요약
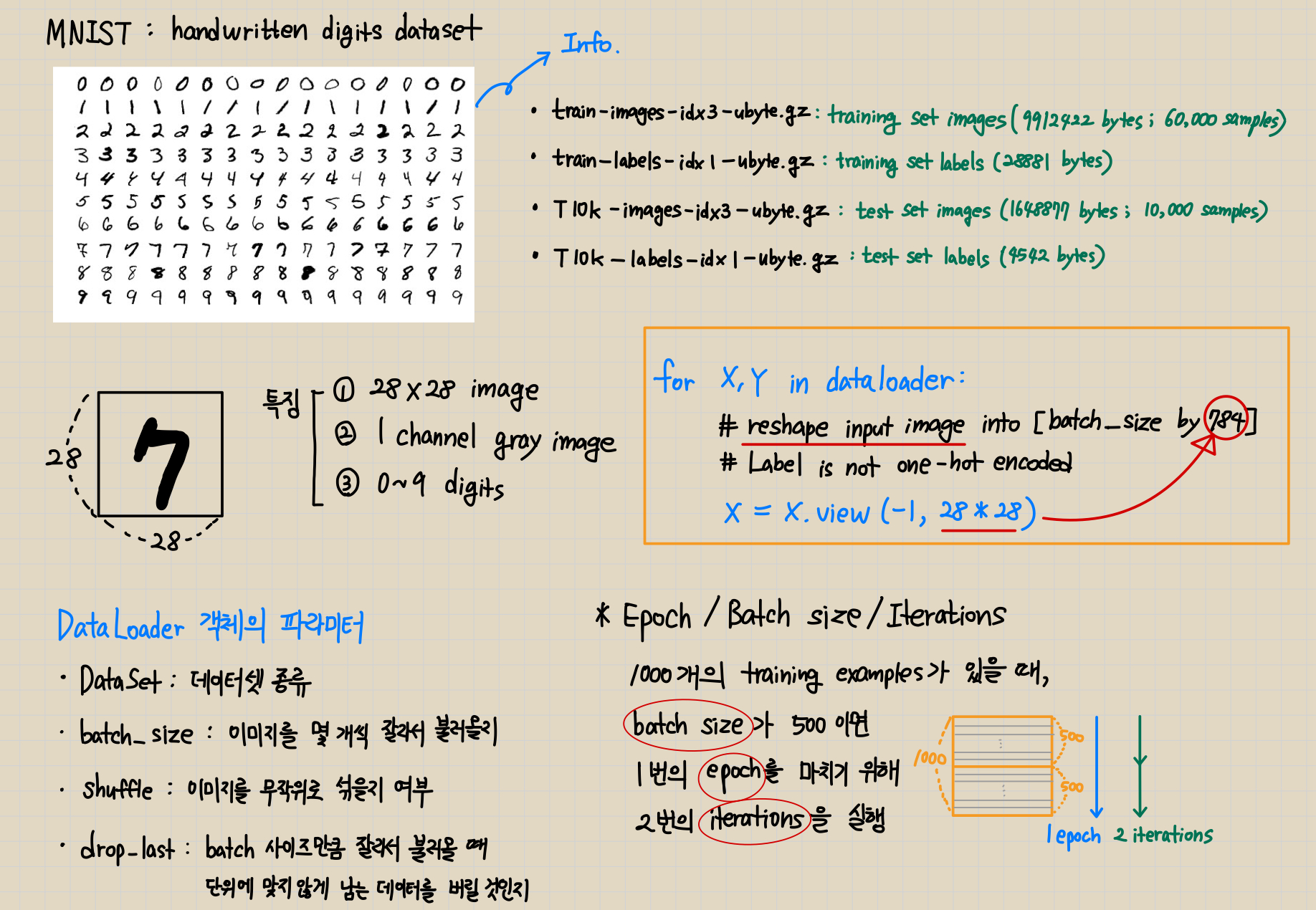
MNIST 데이터셋은 0~9의 숫자를 손으로 작성한 이미지이다. 우체국에서 편지 우편번호를 자동으로 인식하는 기술을 개발하면서 사용되었다. 훈련 데이터를 활용하여 모델을 학습시키고, 테스트 이미지에 어떤 숫자가 있는지 예측할 수 있다.
MNIST 데이터셋, Torchvision 패키지 관련 사이트
- MNIST 데이터셋은 lecun 사이트에서 다운받을 수 있다. Forbidden 에러가 나온다면, Kaggle에서 다운로드해서 사용하거나 구글 코랩에서 실행하는 방법이 있다.
http://yann.lecun.com/exdb/mnist/ - Torchvision 패키지는 컴퓨터 비전 분야에서 널리 사용되는 데이터셋, 모델, 이미지 전처리 도구를 제공한다.
https://pytorch.org/vision/stable/#module-torchvision - Kaggle에서 MNIST 데이터셋을 직접 다운로드할 수 있다.
https://www.kaggle.com/datasets/hojjatk/mnist-dataset?resource=download
MNIST Introduction 구현 코드
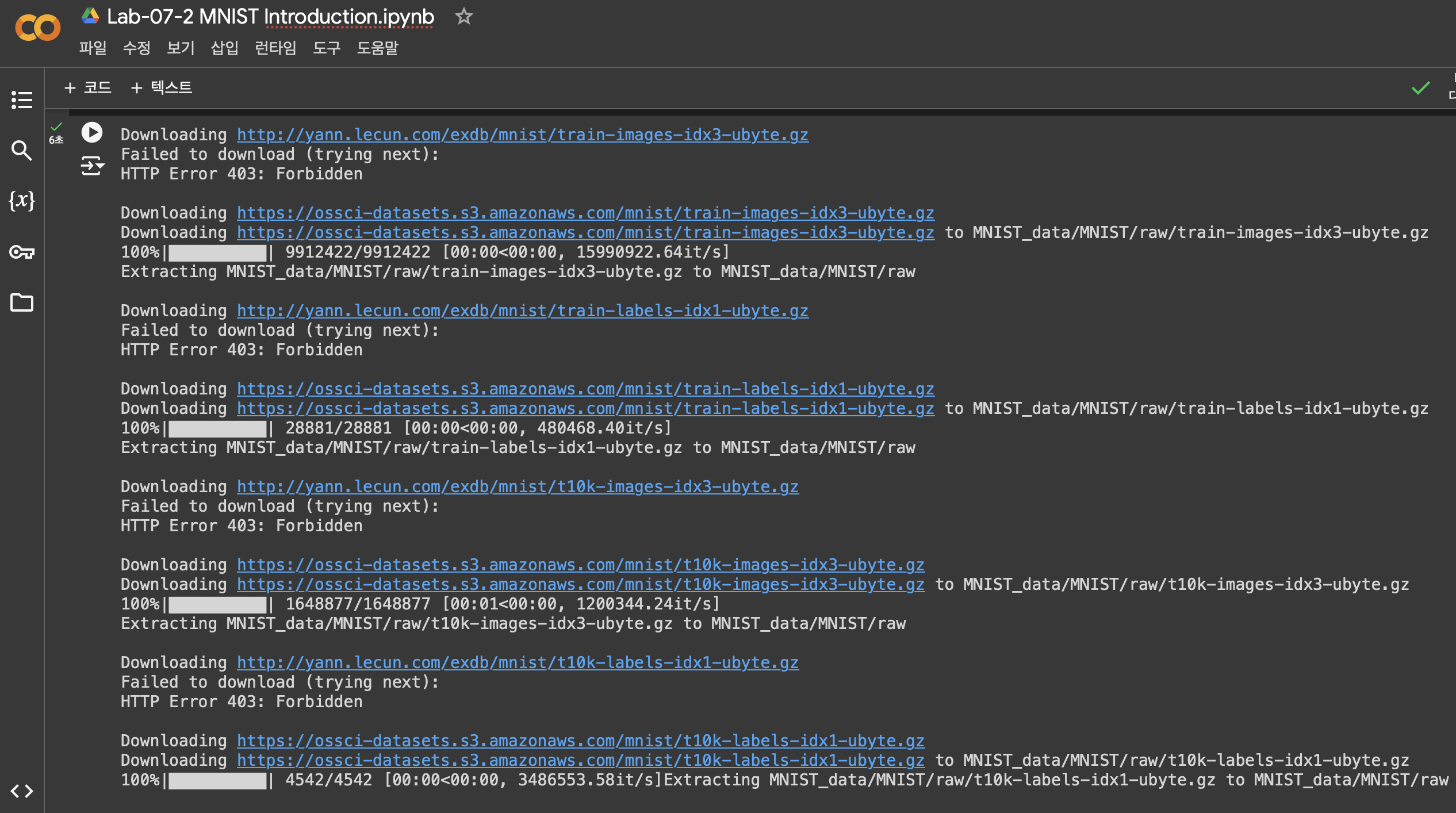
이번 실습은 주피터 노트북이 아닌, 구글 코랩에서 진행했다. torchvision.datasets.MNIST 함수를 통해 lecun 사이트에서 데이터셋을 다운받으려고 했는데, FileNotFoundError가 보였다. 직접 사이트에 들어가서 다운로드 링크를 클릭하니 403 Forbidden 에러가 발생했다.
검색해보니 동일한 에러를 겪는 사람들이 많았는데 설정을 많이 바꿔야 할 것 같아서, 구글 코랩에서 먼저 시도해보았다. 코랩에서도 lecun 사이트 링크는 접근할 수 없었지만, 자동으로 AWS s3 버킷에 저장된 데이터셋을 다운로드하는 것 같았다.

라이브러리 import
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import random
MNIST 데이터셋 다운로드
(실행 환경: 구글 코랩)
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
디바이스 설정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
Epoch와 Batch size 설정
training_epochs = 15
batch_size = 100
Batch 단위로 Train 데이터 입력
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
이미지 Shape 평탄화 & H(x), Cost, 평균 Cost 계산하며 학습 진행
# MNIST data image of shape 28 * 28 = 784
# 10: Number 0~9
linear = torch.nn.Linear(784, 10, bias=True).to(device)
# Define cost & optimizer
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(linear.parameters(), lr=0.1)
for epoch in range(training_epochs):
avg_cost = 0
total_batch = len(data_loader)
for X, Y in data_loader: # X: MNIST images, Y: labels
# Reshape input image into [batch_size by 784]
# Label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
optimizer.zero_grad()
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print("Epoch: {:4d}/{} cost: {:.9f}".format(
epoch + 1, training_epochs, avg_cost
))
평균 예측 Accuracy 계산 & 임의의 Test 이미지의 실제 및 예측 레이블 비교
# Test the model using test sets
with torch.no_grad():
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = linear(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print("Accuracy: ", accuracy.item())
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print("Label:", Y_single_data.item())
single_prediction = linear(X_single_data)
print("Prediction: ", torch.argmax(single_prediction, 1).item())
plt.imshow(mnist_test.test_data[r: r + 1].view(28, 28),
cmap="Greys", interpolation="nearest")
plt.show()실행 결과 분석
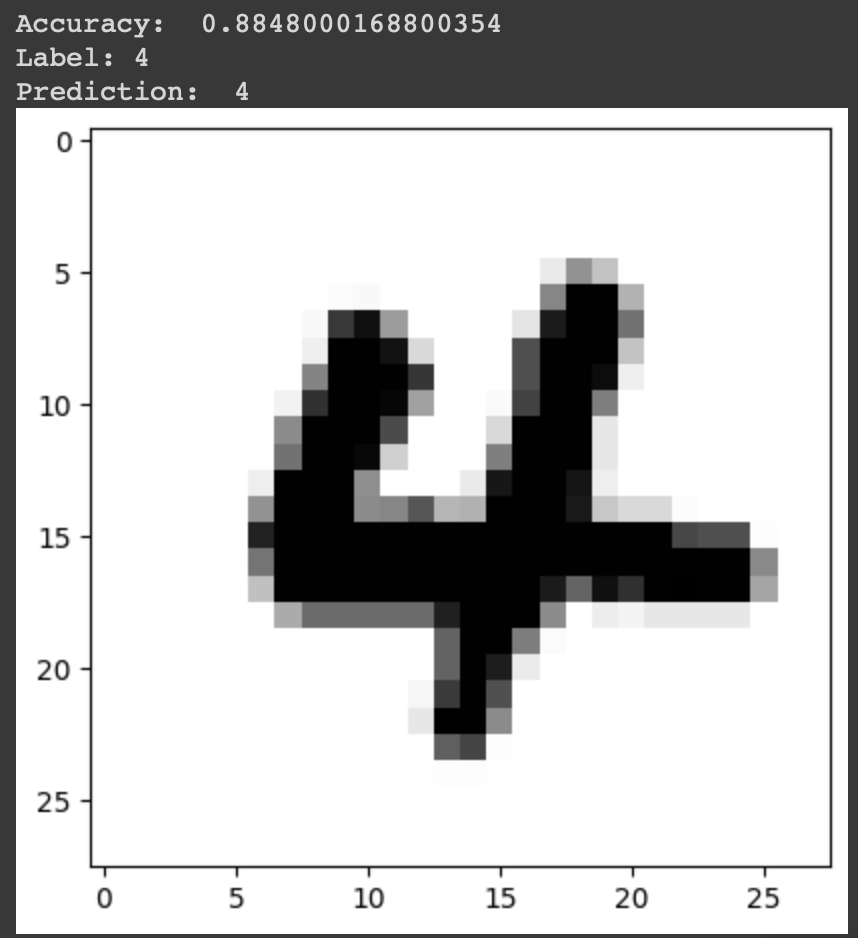
Train 이미지를 1차원 텐서로 평탄화한 후 모델에 학습시켰다. Cost가 약 0.274까지 줄어들며 학습이 진행되었다. 전체 Test 이미지에 대한 예측 정확도는 약 0.885(약 88.5%)로 나타났으며, 무작위로 고른 테스트 이미지의 실제 레이블과 예측 레이블이 일치하는 결과를 볼 수 있었다.

느낀 점
- 예상치 못하게 MNIST 데이터셋을 다운받는 과정에서 어려움이 있었다. 기존 사이트에서 403 에러가 뜨는 것을 발견하고, 스택오버플로우나 깃허브 페이지들을 찾아보다가 방법들이 조금 복잡해 보여서, 구글 코랩에서 실행해 보았다. 자동으로 다운로드할 수 있는 링크를 찾는 걸 보고, 매우 신기했다.
1년 전쯤에, 수업에서 MNIST를 다운받는 코드를 보니, 동일하게 torchvision.datasets.MNIST를 사용했었다. 당시에는 아무 오류도 없었는데, 개발 환경이 달라서 그렇거나 그사이에 데이터 저장 위치가 조금 바뀐 것 같다. - nn.Linear 또는 view 함수에 입력하는 차원과 관련된 파라미터들은 주의 깊게 입력해야겠다. 텐서를 평탄화하는 코드에서 숫자 오타를 내서 에러가 났었다.
- Accuracy가 약 0.885로, 예측이 이루어지긴 했지만 조금 부족하다. 더 복잡한 모델이나 CNN 등을 사용하면 정확도를 높일 수 있을 것 같다.
*참고 자료
모두를 위한 딥러닝 시즌2 - Lab-07-2 MNIST Introduction